Design
Table of Contents
- 146. LRU Cache
- 155. Min Stack
- 173. Binary Search Tree Iterator
- 208. Implement Trie (Prefix Tree)
- 211. Design Add and Search Words Data Structure
- 225. Implement Stack using Queues
- 232. Implement Queue using Stacks
- 284. Peeking Iterator
- 303. Range Sum Query - Immutable
- 304. Range Sum Query 2D - Immutable
- 307. Range Sum Query - Mutable
- 341. Flatten Nested List Iterator
- 355. Design Twitter
- 703. Kth Largest Element in a Stream
- 705. Design HashSet
- 706. Design HashMap
- 933. Number of Recent Calls
- 1603. Design Parking System
- 1656. Design an Ordered Stream
- 3242. Design Neighbor Sum Service
146. LRU Cache
- LeetCode Link: LRU Cache
- Difficulty: Medium
- Topic(s): Design, Hash Table, Linked List
- Company: Twitch
🧠 Problem Statement
Design a data structure that follows the constraints of a Least Recently Used (LRU) cache.
Implement the LRUCache class:
LRUCache(int capacity)Initialize the LRU cache with positive sizecapacity.int get(int key)Return the value of thekeyif the key exists, otherwise return-1.void put(int key, int value)Update the value of thekeyif thekeyexists. Otherwise, add thekey-valuepair to the cache. If the number of keys exceeds thecapacityfrom this operation, evict the least recently used key.
The functions get and put must each run in O(1) average time complexity.
Example 1:
Input
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
Output
[null, null, null, 1, null, -1, null, -1, 3, 4]
Explanation
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // cache is {1=1}
lRUCache.put(2, 2); // cache is {1=1, 2=2}
lRUCache.get(1); // return 1
lRUCache.put(3, 3); // LRU key was 2, evicts key 2, cache is {1=1, 3=3}
lRUCache.get(2); // returns -1 (not found)
lRUCache.put(4, 4); // LRU key was 1, evicts key 1, cache is {4=4, 3=3}
lRUCache.get(1); // return -1 (not found)
lRUCache.get(3); // return 3
lRUCache.get(4); // return 4
🧩 Approach
To implement an LRU Cache, we can use a combination of a hash map and a doubly linked list. The hash map will allow us to access the cache items in O(1) time, while the doubly linked list will help us maintain the order of usage of the cache items. The most recently used item will be at the end of the list, and the least recently used item will be at the beginning of the list. When we access an item, we will move it to the end of the list to mark it as most recently used. When we need to evict an item due to capacity constraints, we will remove the item at the beginning of the list, which is the least recently used item.
💡 Solution
from typing import Optional, Dict
class Node:
def __init__(self, key: int, value: int):
"""Initializes a Node with the given key and value.
Args:
key (int): The key associated with the node.
value (int): The value associated with the node.
Returns:
None
"""
self.key: int = key
self.value: int = value
self.prev: Optional[Node] = None
self.next: Optional[Node] = None
class LRUCache:
def __init__(self, capacity: int):
"""Initializes the LRUCache object with the given capacity.
Args:
capacity (int): The maximum number of items that the cache can hold.
Returns:
None
"""
self.__capacity: int = capacity
self.__hashmap: Dict[int, Node] = {}
self.__left: Node = Node(0, 0)
self.__right: Node = Node(0, 0)
self.__left.next = self.__right
self.__right.prev = self.__left
def __insert(self, node: Node) -> None:
"""Inserts a node at the end of the doubly linked list (right before the right dummy node).
Args:
node (Node): The node to be inserted into the list.
Returns:
None
"""
prev: Node = self.__right.prev
nxt: Node = self.__right
prev.next = node
nxt.prev = node
node.prev = prev
node.next = nxt
def __remove(self, node: Node) -> None:
"""Removes a node from the doubly linked list.
Args:
node (Node): The node to be removed from the list.
Returns:
None
"""
prev: Node = node.prev
nxt: Node = node.next
prev.next = nxt
nxt.prev = prev
def get(self, key: int) -> int:
"""Returns the value of the key if the key exists, otherwise returns -1.
Args:
key (int): The key to be accessed in the cache.
Returns:
int: The value associated with the key if it exists, otherwise -1.
"""
if key in self.__hashmap:
self.__remove(self.__hashmap[key])
self.__insert(self.__hashmap[key])
return self.__hashmap[key].value
return -1
def put(self, key: int, value: int) -> None:
"""Updates the value of the key if the key exists. Otherwise, adds the key-value pair to the cache. If the number of keys exceeds the capacity from this operation, evicts the least recently used key.
Args:
key (int): The key to be added or updated in the cache.
value (int): The value to be associated with the key.
Returns:
None
"""
if key in self.__hashmap:
self.__remove(self.__hashmap[key])
self.__hashmap[key] = Node(key, value)
self.__insert(self.__hashmap[key])
if len(self.__hashmap) > self.__capacity:
lru: Node = self.__left.next
self.__remove(lru)
del self.__hashmap[lru.key]
🧮 Complexity Analysis
- Time Complexity:
get:O(1)put:O(1)
- Space Complexity:
O(n)wherenis the capacity of the cache.
155. Min Stack
- LeetCode Link: Min Stack
- Difficulty: Easy
- Topic(s): Design, Stack
- Company: Amazon
🧠 Problem Statement
Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.
Implement the
MinStackclass:
MinStack()initializes the stack object.void push(int val)pushes the elementvalonto the stack.void pop()removes the element on the top of the stack.int top()gets the top element of the stack.int getMin()retrieves the minimum element in the stack.You must implement a solution with
O(1)time complexity for each function.Example 1:
Input ["MinStack","push","push","push","getMin","pop","top","getMin"] [[],[-2],[0],[-3],[],[],[],[]] Output [null,null,null,null,-3,null,0,-2] Explanation MinStack minStack = new MinStack(); minStack.push(-2); minStack.push(0); minStack.push(-3); minStack.getMin(); // return -3 minStack.pop(); minStack.top(); // return 0 minStack.getMin(); // return -2
🧩 Approach
To implement a stack that supports retrieving the minimum element in constant time, we can use two stacks. The first stack will be used to store all the elements of the stack, while the second stack will be used to keep track of the minimum elements. Whenever we push a new element onto the main stack, we compare it with the current minimum (the top of the minimum stack). If the new element is smaller than or equal to the current minimum, we also push it onto the minimum stack. When we pop an element from the main stack, if that element is the same as the current minimum, we also pop it from the minimum stack. This way, the top of the minimum stack will always represent the minimum element in the main stack.
💡 Solution
from typing import List
class MinStack:
def __init__(self):
self.__stack: List[int] = []
self.__minStack: List[int] = []
def push(self, val: int) -> None:
"""Pushes an element onto the stack and updates the minimum stack if necessary.
Args:
val (int): The value to be pushed onto the stack.
Returns:
None
"""
self.__stack.append(val)
val: int = min(val, self.__minStack[-1] if self.__minStack else val)
self.__minStack.append(val)
def pop(self) -> None:
"""Removes the element on the top of the stack and updates the minimum stack if necessary.
Args:
None
Returns:
None
"""
self.__stack.pop()
self.__minStack.pop()
def top(self) -> int:
"""Returns the top element of the stack.
Args:
None
Returns:
int: The element at the top of the stack.
"""
return self.__stack[-1]
def getMin(self) -> int:
"""Retrieves the minimum element in the stack.
Args:
None
Returns:
int: The minimum element in the stack.
"""
return self.__minStack[-1]
🧮 Complexity Analysis
- Time Complexity:
push:O(1)pop:O(1)top:O(1)getMin:O(1)
- Space Complexity:
O(n)wherenis the number of elements in the stack.
173. Binary Search Tree Iterator
- LeetCode Link: Binary Search Tree Iterator
- Difficulty: Medium
- Topic(s): Design, Tree, Stack
- Company: Meta
🧠 Problem Statement
Implement the
BSTIteratorclass that represents an iterator over the in-order traversal of a binary search tree (BST):
BSTIterator(TreeNode root)Initializes an object of theBSTIteratorclass. Therootof the BST is given as part of the constructor. The pointer should be initialized to a non-existent number smaller than any element in the BST.boolean hasNext()Returnstrueif there exists a number in the traversal to the right of the pointer, otherwise returnsfalse.int next()Moves the pointer to the right, then returns the number at the pointer.Notice that by initializing the pointer to a non-existent smallest number, the first call to
next()will return the smallest element in the BST.You may assume that
next()calls will always be valid. That is, there will be at least a next number in the in-order traversal whennext()is called.Example 1:
Input ["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"] [[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []] Output [null, 3, 7, true, 9, true, 15, true, 20, false] Explanation BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]); bSTIterator.next(); // return 3 bSTIterator.next(); // return 7 bSTIterator.hasNext(); // return True bSTIterator.next(); // return 9 bSTIterator.hasNext(); // return True bSTIterator.next(); // return 15 bSTIterator.hasNext(); // return True bSTIterator.next(); // return 20 bSTIterator.hasNext(); // return False
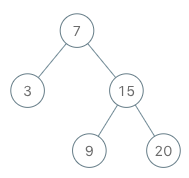
🧩 Approach
To implement the BSTIterator, we can use a stack to simulate the in-order traversal of the binary search tree. The idea is to push all the left children of the current node onto the stack until we reach a leaf node. When we call next(), we pop the top node from the stack, which will be the next smallest element in the BST. After popping a node, we need to consider its right child and push all of its left children onto the stack as well. This way, we maintain the invariant that the top of the stack always contains the next smallest element in the BST.
💡 Solution
from typing import Optional, List
class TreeNode:
def __init__(self, val=0, left=None, right=None):
"""Initializes a TreeNode with the given value and optional left and right children.
Args:
val (int): The value of the node. Default is 0.
left (Optional[TreeNode]): The left child of the node. Default is None.
right (Optional[TreeNode]): The right child of the node. Default is None.
Returns:
None
"""
self.val: int = val
self.left: Optional[TreeNode] = left
self.right: Optional[TreeNode] = right
class BSTIterator:
def __init__(self, root: Optional[TreeNode]):
"""Initializes the BSTIterator object with the given root of the binary search tree.
Args:
root (Optional[TreeNode]): The root of the binary search tree.
Returns:
None
"""
self.__stack: List[TreeNode] = []
while root:
self.__stack.append(root)
root = root.left
def next(self) -> int:
"""Moves the pointer to the right, then returns the number at the pointer.
Args:
None
Returns:
int: The next number in the in-order traversal of the BST.
"""
res: TreeNode = self.__stack.pop()
cur: TreeNode = res.right
while cur:
self.__stack.append(cur)
cur = cur.left
return res.val
def hasNext(self) -> bool:
"""Returns whether there exists a number in the traversal to the right of the pointer.
Args:
None
Returns:
bool: True if there exists a next number in the in-order traversal, False otherwise.
"""
return self.__stack != []
🧮 Complexity Analysis
-
Time Complexity:
next:O(1)amortizedhasNext:O(1)
-
Space Complexity:
O(h)wherehis the height of the binary search tree.
208. Implement Trie (Prefix Tree)
- LeetCode Link: Implement Trie (Prefix Tree)
- Difficulty: Medium
- Topic(s): Design, Trie
- Company: Microsoft
🧠 Problem Statement
A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:
Trie()Initializes the trie object.void insert(String word)Inserts the stringwordinto the trie.boolean search(String word)Returnstrueif the stringwordis in the trie (i.e., was inserted before), andfalseotherwise.boolean startsWith(String prefix)Returnstrueif there is a previously inserted stringwordthat has the prefixprefix, andfalseotherwise.Example 1:
Input ["Trie", "insert", "search", "search", "startsWith", "insert", "search"] [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]] Output [null, null, true, false, true, null, true] Explanation Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // return True trie.search("app"); // return False trie.startsWith("app"); // return True trie.insert("app"); trie.search("app"); // return True
🧩 Approach
To implement a Trie (Prefix Tree), we can define a TrieNode class that represents each node in the trie. Each TrieNode will contain a dictionary of its children nodes and a boolean flag to indicate whether it represents the end of a word. The Trie class will use the TrieNode to build the trie structure. The insert method will add words to the trie, the search method will check for the existence of a word, and the startsWith method will check for the existence of any word that starts with a given prefix.
💡 Solution
from typing import Dict
class TrieNode:
def __init__(self):
"""Initializes a TrieNode with an empty dictionary of children and a boolean flag to indicate the end of a word.
Args:
None
Returns:
None
"""
self.children: Dict[str, TrieNode] = {}
self.endOfWord: bool = False
class Trie:
def __init__(self):
"""Initializes the Trie object.
Args:
None
Returns:
None
"""
self.__root = TrieNode()
def insert(self, word: str) -> None:
"""Inserts the string word into the trie.
Args:
word (str): The string to be inserted into the trie.
Returns:
None
"""
cur: TrieNode = self.__root
for c in word:
if c not in cur.children:
cur.children[c] = TrieNode()
cur = cur.children[c]
cur.endOfWord = True
def search(self, word: str) -> bool:
"""Returns true if the string word is in the trie, and false otherwise.
Args:
word (str): The string to be searched in the trie.
Returns:
bool: True if the string is in the trie, False otherwise.
"""
cur: TrieNode = self.__root
for c in word:
if c not in cur.children:
return False
cur = cur.children[c]
return cur.endOfWord
def startsWith(self, prefix: str) -> bool:
"""Returns true if there is a previously inserted string word that has the prefix prefix, and false otherwise.
Args:
prefix (str): The prefix to be searched in the trie.
Returns:
bool: True if there is a string in the trie that starts with the prefix, False otherwise.
"""
cur: TrieNode = self.__root
for c in prefix:
if c not in cur.children:
return False
cur = cur.children[c]
return True
🧮 Complexity Analysis
- Time Complexity:
insert:O(m)wheremis the length of the word being inserted.search:O(m)wheremis the length of the word being searched.startsWith:O(m)wheremis the length of the prefix being searched.
- Space Complexity:
O(n * m)wherenis the number of words inserted into the trie andmis the average length of the words. In the worst case, if all words are unique and have no common prefixes, the space complexity can beO(n * m). However, if many words share common prefixes, the space complexity can be significantly reduced.
211. Design Add and Search Words Data Structure
- LeetCode Link: Design Add and Search Words Data Structure
- Difficulty: Medium
- Topic(s): Design, Trie, Backtracking
- Company: Google
🧠 Problem Statement
Design a data structure that supports adding new words and finding if a string matches any previously added string.
Implement the
WordDictionaryclass:
WordDictionary()Initializes the object.void addWord(word)Addswordto the data structure, it can be matched later.bool search(word)Returnstrueif there is any string in the data structure that matcheswordorfalseotherwise.wordmay contain dots'.'where dots can be matched with any letter.Example:
Input ["WordDictionary","addWord","addWord","addWord","search","search","search","search"] [[],["bad"],["dad"],["mad"],["pad"],["bad"],[".ad"],["b.."]] Output [null,null,null,null,false,true,true,true] Explanation WordDictionary wordDictionary = new WordDictionary(); wordDictionary.addWord("bad"); wordDictionary.addWord("dad"); wordDictionary.addWord("mad"); wordDictionary.search("pad"); // return False wordDictionary.search("bad"); // return True wordDictionary.search(".ad"); // return True wordDictionary.search("b.."); // return True
🧩 Approach
To implement the WordDictionary, we can use a Trie (Prefix Tree) data structure to store the added words. The addWord method will insert words into the trie, while the search method will perform a depth-first search (DFS) to handle the case where the search word may contain dots '.'. When we encounter a dot in the search word, we need to explore all possible child nodes at that position in the trie. If we reach the end of the search word and find a node that marks the end of a valid word, we return true. If we exhaust all possibilities without finding a match, we return false.
💡 Solution
from typing import Dict
class TrieNode:
def __init__(self):
"""Initializes a TrieNode with an empty dictionary of children and a boolean flag to indicate the end of a word.
Args:
None
Returns:
None
"""
self.children: Dict[str, TrieNode] = {}
self.endOfWord: bool = False
class WordDictionary:
def __init__(self):
"""Initializes the WordDictionary object.
Args:
None
Returns:
None
"""
self.__root = TrieNode()
def addWord(self, word: str) -> None:
"""Adds word to the data structure, it can be matched later.
Args:
word (str): The word to be added to the data structure.
Returns:
None
"""
cur: TrieNode = self.__root
for c in word:
if c not in cur.children:
cur.children[c] = TrieNode()
cur = cur.children[c]
cur.endOfWord = True
def search(self, word: str) -> bool:
"""Returns true if there is any string in the data structure that matches word or false otherwise. word may contain dots '.' where dots can be matched with any letter.
Args:
word (str): The word to be searched in the data structure. It may contain dots '.'.
Returns:
bool: True if there is a string in the data structure that matches the word, False otherwise.
"""
def dfs(j, root):
cur: TrieNode = root
for i in range(j, len(word)):
c: str = word[i]
if c == ".":
for child in cur.children.values():
if dfs(i + 1, child):
return True
return False
else:
if c not in cur.children:
return False
cur = cur.children[c]
return cur.endOfWord
return dfs(0, self.__root)
🧮 Complexity Analysis
- Time Complexity:
addWord:O(m)wheremis the length of the word being added.search: In the worst case, if the search word contains only dots, the time complexity can beO(n * m)wherenis the number of words in the data structure andmis the average length of the words. However, if there are fewer dots and more specific characters, the time complexity can be significantly reduced.
- Space Complexity:
O(n * m)wherenis the number of words added to the data structure andmis the average length of the words. In the worst case, if all words are unique and have no common prefixes, the space complexity can beO(n * m). However, if many words share common prefixes, the space complexity can be significantly reduced.
225. Implement Stack using Queues
- LeetCode Link: Implement Stack using Queues
- Difficulty: Easy
- Topic(s): Design, Queue, Stack
- Company: Google
🧠 Problem Statement
Implement a last-in-first-out (LIFO) stack using only two queues. The implemented stack should support all the functions of a normal stack (
push,top,pop, andempty).Implement the
MyStackclass:
void push(int x)Pushes element x to the top of the stack.int pop()Removes the element on the top of the stack and returns it.int top()Returns the element on the top of the stack.boolean empty()Returnstrueif the stack is empty,falseotherwise.Notes:
- You must use only standard operations of a queue, which means that only
push to back,peek/pop from front,sizeandis emptyoperations are valid.- Depending on your language, the queue may not be supported natively. You may simulate a queue using a list or deque (double-ended queue) as long as you use only a queue’s standard operations.
Example 1:
Input ["MyStack", "push", "push", "top", "pop", "empty"] [[], [1], [2], [], [], []] Output [null, null, null, 2, 2, false] Explanation MyStack myStack = new MyStack(); myStack.push(1); myStack.push(2); myStack.top(); // return 2 myStack.pop(); // return 2 myStack.empty(); // return False
🧩 Approach
To implement a stack using queues, we can use a single queue to store the elements of the stack. The main idea is to ensure that the most recently added element (the top of the stack) is always at the front of the queue. This way, we can perform pop and top operations in O(1) time. To achieve this, when we pop a new element onto the stack, we can enqueue it to the back of the queue and then rotate the queue by dequeuing all elements before it and enqueuing them back to the end of the queue. This way, the new element will be at the front of the queue, representing the top of the stack.
💡 Solution
from collections import deque
class MyStack:
def __init__(self):
"""Initializes an empty stack."""
self.__q: deque[int] = deque()
def push(self, x: int) -> None:
"""Pushes an element onto the top of the stack.
Args:
x (int): The value to be pushed onto the stack.
Returns:
None
"""
self.__q.append(x)
def pop(self) -> int:
"""Removes and returns the top element of the stack.
Args:
None
Returns:
int: The element removed from the top of the stack.
"""
for _ in range(len(self.__q) - 1):
self.__q.append(self.__q.popleft())
return self.__q.popleft()
def top(self) -> int:
"""Returns the top element of the stack without removing it.
Args:
None
Returns:
int: The element at the top of the stack.
"""
return self.__q[-1]
def empty(self) -> bool:
"""Checks whether the stack is empty.
Args:
None
Returns:
bool: True if the stack is empty, False otherwise.
"""
return not self.__q
🧮 Complexity Analysis
- Time Complexity:
push:O(1)pop:O(n)top:O(1)empty:O(1)
- Space Complexity:
O(n)
232. Implement Queue using Stacks
- LeetCode Link: Implement Queue using Stacks
- Difficulty: Easy
- Topic(s): Design, Queue, Stack
- Company: Microsoft
🧠 Problem Statement
Implement a first in first out (FIFO) queue using only two stacks. The implemented queue should support all the functions of a normal queue (
push,peek,pop, andempty).Implement the
MyQueueclass:
void push(int x)Pushes element x to the back of the queue.int pop()Removes the element from the front of the queue and returns it.int peek()Returns the element at the front of the queue.boolean empty()Returnstrueif the queue is empty,falseotherwise.Notes:
You must use only standard operations of a stack, which means only
push to top,peek/pop from top,size, andis emptyoperations are valid. Depending on your language, the stack may not be supported natively. You may simulate a stack using a list or deque (double-ended queue) as long as you use only a stack’s standard operations.Example 1:
Input ["MyQueue", "push", "push", "peek", "pop", "empty"] [[], [1], [2], [], [], []] Output [null, null, null, 1, 1, false] Explanation MyQueue myQueue = new MyQueue(); myQueue.push(1); // queue is: [1] myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue) myQueue.peek(); // return 1 myQueue.pop(); // return 1, queue is [2] myQueue.empty(); // return false
🧩 Approach
To implement a queue using stacks, we can use two stacks to manage the elements of the queue. The main idea is to use one stack (s1) for enqueueing elements and another stack (s2) for dequeueing elements. When we need to dequeue an element, if s2 is empty, we can pop all elements from s1 and push them onto s2, which will reverse the order of the elements and allow us to access the front of the queue. This way, we can perform push, pop, and peek operations efficiently.
💡 Solution
from typing import List
class MyQueue:
def __init__(self):
"""Initializes an empty queue using two stacks."""
self.__s1: List[int] = []
self.__s2: List[int] = []
def push(self, x: int) -> None:
"""Pushes an element to the back of the queue.
Args:
x (int): The value to be pushed onto the queue.
Returns:
None
"""
self.__s1.append(x)
def pop(self) -> int:
"""Removes and returns the front element of the queue.
Args:
None
Returns:
int: The element removed from the front of the queue.
"""
if not self.__s2:
while self.__s1:
self.__s2.append(self.__s1.pop())
return self.__s2.pop()
def peek(self) -> int:
"""Returns the front element of the queue without removing it.
Args:
None
Returns:
int: The element at the front of the queue.
"""
if not self.__s2:
while self.__s1:
self.__s2.append(self.__s1.pop())
return self.__s2[-1]
def empty(self) -> bool:
"""Checks whether the queue is empty.
Args:
None
Returns:
bool: True if the queue is empty, False otherwise.
"""
return max(len(self.__s1), len(self.__s2)) == 0
🧮 Complexity Analysis
- Time Complexity:
push:O(1)pop:O(1)amortizedpeek:O(1)amortizedempty:O(1)
- Space Complexity:
O(n)
284. Peeking Iterator
- LeetCode Link: Peeking Iterator
- Difficulty: Medium
- Topic(s): Design, Iterator
- Company: Google
🧠 Problem Statement
Design an iterator that supports the
peekoperation on an existing iterator in addition to thehasNextand thenextoperations.Implement the
PeekingIteratorclass:
PeekingIterator(Iterator<int> nums)Initializes the object with the given integer iteratoriterator.int next()Returns the next element in the array and moves the pointer to the next element.boolean hasNext()Returnstrueif there are still elements in the array.int peek()Returns the next element in the array without moving the pointer.Note: Each language may have a different implementation of the constructor and
Iterator, but they all support the intnext()andboolean hasNext()functions.Example 1:
Input ["PeekingIterator", "next", "peek", "next", "next", "hasNext"] [[[1, 2, 3]], [], [], [], [], []] Output [null, 1, 2, 2, 3, false] Explanation PeekingIterator peekingIterator = new PeekingIterator([1, 2, 3]); // [1,2,3] peekingIterator.next(); // return 1, the pointer moves to the next element [1,2,3]. peekingIterator.peek(); // return 2, the pointer does not move [1,2,3]. peekingIterator.next(); // return 2, the pointer moves to the next element [1,2,3] peekingIterator.next(); // return 3, the pointer moves to the next element [1,2,3] peekingIterator.hasNext(); // return False
🧩 Approach
To implement the PeekingIterator, we can maintain a cache to store the next element of the iterator. This way, we can return the next element in constant time when peek() is called without advancing the iterator. When next() is called, we can return the cached value and then update the cache with the next element from the iterator. The hasNext() method can simply check if there is a cached value available.
💡 Solution
# Below is the interface for Iterator, which is already defined for you.
#
# class Iterator:
# def __init__(self, nums):
# """Initializes an iterator object to the beginning of a list.
#
# Args:
# nums (List[int]): The list of integers to iterate over.
#
# Returns:
# None
# """
#
# def hasNext(self):
# """Returns true if the iteration has more elements.
#
# Args:
# None
#
# Returns:
# bool: True if there are more elements to iterate over, False otherwise.
# """
#
# def next(self):
# """Returns the next element in the iteration.
#
# Args:
# None
# Returns:
# int: The next element in the iteration.
# """
class PeekingIterator:
def __init__(self, iterator):
"""Initializes the PeekingIterator with the given iterator.
Args:
iterator (Iterator): The input iterator to be wrapped by the PeekingIterator.
Returns:
None
"""
self.__iterator: Iterator = iterator
self.__cache: int = None
self.__peekCache()
def __peekCache(self) -> None:
"""Updates the cache with the next element from the iterator if it exists, otherwise sets it to None.
Args:
None
Returns:
None
"""
if self.__iterator.hasNext():
self.__cache = self.__iterator.next()
else:
self.__cache = None
def peek(self):
"""Returns the next element in the array without moving the pointer.
Args:
None
Returns:
int: The next element in the array.
"""
return self.__cache
def next(self) -> int:
"""Returns the next element in the array and moves the pointer to the next element.
Args:
None
Returns:
int: The next element in the array.
"""
peek: int = self.__cache
self.__peekCache()
return peek
def hasNext(self) -> bool:
"""Returns true if there are still elements in the array.
Args:
None
Returns:
bool: True if there are still elements in the array, False otherwise.
"""
return self.__cache is not None
🧮 Complexity Analysis
- Time Complexity:
peek:O(1)next:O(1)hasNext:O(1)
- Space Complexity:
O(1)
303. Range Sum Query - Immutable
- LeetCode Link: Range Sum Query - Immutable
- Difficulty: Easy
- Topic(s): Design, Array, Prefix Sum
- Company: Amazon
🧠 Problem Statement
Given an integer array
nums, handle multiple queries of the following type:Calculate the sum of the elements of
numsbetween indicesleftandrightinclusive whereleft <= right.Implement the
NumArrayclass:
NumArray(int[] nums)Initializes the object with the integer arraynums.int sumRange(int left, int right)Returns the sum of the elements ofnumsbetween indicesleftandrightinclusive (i.e.nums[left] + nums[left + 1] + ... + nums[right]).Example 1:
Input ["NumArray", "sumRange", "sumRange", "sumRange"] [[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]] Output [null, 1, -1, -3] Explanation NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]); numArray.sumRange(0, 2); // return (-2) + 0 + 3 = 1 numArray.sumRange(2, 5); // return 3 + (-5) + 2 + (-1) = -1 numArray.sumRange(0, 5); // return (-2) + 0 + 3 + (-5) + 2 + (-1) = -3
🧩 Approach
To efficiently calculate the sum of elements in a given range, we can use a prefix sum array. The prefix sum array allows us to compute the sum of any subarray in constant time after an initial preprocessing step. The idea is to create a prefix sum array where each element at index i contains the sum of all elements from the start of the original array up to index i. Then, to calculate the sum of elements between indices left and right, we can simply subtract the prefix sum at left - 1 from the prefix sum at right.
💡 Solution
from typing import List
class NumArray:
def __init__(self, nums: List[int]):
"""Initializes the NumArray object with the given integer array.
Args:
nums (List[int]): The input integer array.
Returns:
None
"""
self.__prefix: List[int] = []
cur: int = 0
for n in nums:
cur += n
self.__prefix.append(cur)
def sumRange(self, left: int, right: int) -> int:
"""Returns the sum of the elements of nums between indices left and right inclusive.
Args:
left (int): The starting index of the range.
right (int): The ending index of the range.
Returns:
int: The sum of the elements in the specified range.
"""
rightSum: int = self.__prefix[right]
leftSum: int = self.__prefix[left - 1] if left > 0 else 0
return rightSum - leftSum
🧮 Complexity Analysis
- Time Complexity:
__init__:O(n)for preprocessing the prefix sum array.sumRange:O(1)for each query after preprocessing.
- Space Complexity:
O(n)
304. Range Sum Query 2D - Immutable
- LeetCode Link: Range Sum Query 2D - Immutable
- Difficulty: Medium
- Topic(s): Design, Array, Prefix Sum
- Company: Amazon
🧠 Problem Statement
Given a 2D matrix
matrix, handle multiple queries of the following type:
- Calculate the sum of the elements of
matrixinside the rectangle defined by its upper left corner(row1, col1)and lower right corner(row2, col2).Implement the NumMatrix class:
NumMatrix(int[][] matrix)Initializes the object with the integer matrixmatrix.int sumRegion(int row1, int col1, int row2, int col2)Returns the sum of the elements ofmatrixinside the rectangle defined by its upper left corner(row1, col1)and lower right corner(row2, col2).You must design an algorithm where
sumRegionworks onO(1)time complexity.Example 1:
Input ["NumMatrix", "sumRegion", "sumRegion", "sumRegion"] [[[[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]], [2, 1, 4, 3], [1, 1, 2, 2], [1, 2, 2, 4]] Output [null, 8, 11, 12] Explanation NumMatrix numMatrix = new NumMatrix([[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]); numMatrix.sumRegion(2, 1, 4, 3); // return 8 (i.e sum of the red rectangle) numMatrix.sumRegion(1, 1, 2, 2); // return 11 (i.e sum of the green rectangle) numMatrix.sumRegion(1, 2, 2, 4); // return 12 (i.e sum of the blue rectangle)
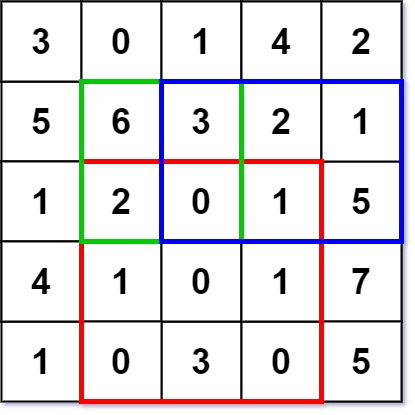
🧩 Approach
To efficiently calculate the sum of elements in a given rectangular region of a 2D matrix, we can use a 2D prefix sum matrix. The prefix sum matrix allows us to compute the sum of any submatrix in constant time after an initial preprocessing step. The idea is to create a prefix sum matrix where each element at index (i, j) contains the sum of all elements from the top-left corner of the original matrix up to index (i, j). Then, to calculate the sum of elements in the rectangle defined by (row1, col1) and (row2, col2), we can use the inclusion-exclusion principle to combine the relevant prefix sums.
💡 Solution
from typing import List
class NumMatrix:
def __init__(self, matrix: List[List[int]]):
"""Initializes the NumMatrix object with the given 2D integer matrix.
Args:
matrix (List[List[int]]): The input 2D integer matrix.
Returns:
None
"""
R, C = len(matrix), len(matrix[0])
self.__sumMat: List[List[int]] = [[0] * (C + 1) for _ in range(R + 1)]
for r in range(R):
prefix: int = 0
for c in range(C):
prefix += matrix[r][c]
above: int = self.__sumMat[r][c + 1]
self.__sumMat[r + 1][c + 1] = prefix + above
def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:
"""Returns the sum of the elements of matrix inside the rectangle defined by its upper left corner (row1, col1) and lower right corner (row2, col2).
Args:
row1 (int): The row index of the upper left corner of the rectangle.
col1 (int): The column index of the upper left corner of the rectangle.
row2 (int): The row index of the lower right corner of the rectangle.
col2 (int): The column index of the lower right corner of the rectangle.
Returns:
int: The sum of the elements in the specified rectangle.
"""
row1, col1, row2, col2 = row1 + 1, col1 + 1, row2 + 1, col2 + 1
bottomRight: int = self.__sumMat[row2][col2]
above: int = self.__sumMat[row1 - 1][col2]
left: int = self.__sumMat[row2][col1 - 1]
topLeft: int = self.__sumMat[row1 - 1][col1 - 1]
return bottomRight - above - left + topLeft
🧮 Complexity Analysis
- Time Complexity:
__init__:O(R * C)for preprocessing the prefix sum matrix.sumRegion:O(1)for each query after preprocessing.
- Space Complexity:
O(R * C)for storing the prefix sum matrix.
307. Range Sum Query - Mutable
- LeetCode Link: Range Sum Query - Mutable
- Difficulty: Medium
- Topic(s): Design, Array, Segment Tree, Binary Indexed Tree
- Company: Amazon
🧠 Problem Statement
Given an integer array
nums, handle multiple queries of the following types:
- Update the value of an element in
nums.- Calculate the sum of the elements of
numsbetween indicesleftandrightinclusive whereleft<=right.Implement the
NumArrayclass:
NumArray(int[] nums)Initializes the object with the integer arraynums.void update(int index, int val)Updates the value ofnums[index]to beval.int sumRange(int left, int right)Returns the sum of the elements ofnumsbetween indicesleftandrightinclusive (i.e.nums[left] + nums[left + 1] + ... + nums[right]).Example 1:
Input ["NumArray", "sumRange", "update", "sumRange"] [[[1, 3, 5]], [0, 2], [1, 2], [0, 2]] Output [null, 9, null, 8] Explanation NumArray numArray = new NumArray([1, 3, 5]); numArray.sumRange(0, 2); // return 1 + 3 + 5 = 9 numArray.update(1, 2); // nums = [1, 2, 5] numArray.sumRange(0, 2); // return 1 + 2 + 5 = 8
🧩 Approach
To efficiently handle updates and range sum queries on an array, we can use a Segment Tree data structure. A Segment Tree allows us to perform both update and query operations in logarithmic time. The idea is to build a binary tree where each node represents a segment of the array and stores the sum of that segment. When we need to update an element, we can update the corresponding leaf node and then propagate the changes up the tree. When we need to calculate the sum of a range, we can traverse the tree and combine the sums of the relevant segments.
💡 Solution
from typing import List
class Node:
def __init__(self, start, end):
"""Initializes a Node in the Segment Tree with the given start and end indices.
Args:
start (int): The starting index of the segment represented by this node.
end (int): The ending index of the segment represented by this node.
Returns:
None
"""
self.start: int = start
self.end: int = end
self.total: int = 0
self.left: Node = None
self.right: Node = None
class NumArray:
def __init__(self, nums: List[int]):
"""Initializes the NumArray object with the given integer array.
Args:
nums (List[int]): The input integer array.
Returns:
None
"""
def createTree(nums: List[int], l: int, r: int) -> Node:
"""Recursively builds a segment tree from the input array nums between indices l and r.
Args:
nums (List[int]): The input array of integers.
l (int): The left index of the current segment.
r (int): The right index of the current segment.
Returns:
Node: The root node of the segment tree for the current segment.
"""
if l > r:
return None
if l == r:
n: Node = Node(l, r)
n.total = nums[l]
return n
mid: int = (l + r) // 2
root: Node = Node(l, r)
root.left = createTree(nums, l, mid)
root.right = createTree(nums, mid + 1, r)
root.total = root.left.total + root.right.total
return root
self.root: Node = createTree(nums, 0, len(nums) - 1)
def update(self, index: int, val: int) -> None:
"""Updates the value at the specified index in the array and updates the segment tree accordingly.
Args:
index (int): The index of the element to be updated.
val (int): The new value to be set at the specified index.
Returns:
None
"""
def updateVal(root: Node, i: int, val: int) -> int:
"""Recursively updates the value at index i in the segment tree rooted at root and updates the total values of the affected nodes.
Args:
root (Node): The current node in the segment tree.
i (int): The index of the element to be updated.
val (int): The new value to be set at the specified index.
Returns:
int: The updated total value of the current node after the update.
"""
if root.left == root.right:
root.total = val
return val
mid: int = (root.start + root.end) // 2
if i <= mid:
updateVal(root.left, i, val)
else:
updateVal(root.right, i, val)
root.total = root.left.total + root.right.total
return root.total
updateVal(self.root, index, val)
def sumRange(self, left: int, right: int) -> int:
"""Returns the sum of the elements of the array between indices left and right inclusive.
Args:
left (int): The starting index of the range.
right (int): The ending index of the range.
Returns:
int: The sum of the elements in the specified range.
"""
def rangeSum(root: Node, i: int, j: int) -> int:
"""Recursively calculates the sum of the elements in the range [i, j] in the segment tree rooted at root.
Args:
root (Node): The current node in the segment tree.
i (int): The starting index of the range.
j (int): The ending index of the range.
Returns:
int: The sum of the elements in the specified range.
"""
if root.start == i and root.end == j:
return root.total
mid: int = (root.start + root.end) // 2
if j <= mid:
return rangeSum(root.left, i, j)
elif i >= mid + 1:
return rangeSum(root.right, i, j)
else:
return rangeSum(root.left, i, mid) + rangeSum(root.right, mid + 1, j)
return rangeSum(self.root, left, right)
🧮 Complexity Analysis
- Time Complexity:
__init__:O(n)for building the segment tree.update:O(log n)for updating an element in the segment tree.sumRange:O(log n)for querying the sum of a range in the segment tree.
- Space Complexity:
O(n)for storing the segment tree.
341. Flatten Nested List Iterator
- LeetCode Link: Flatten Nested List Iterator
- Difficulty: Medium
- Topic(s): Design, Stack, Iterator
- Company: Google
🧠 Problem Statement
You are given a nested list of integers
nestedList. Each element is either an integer or a list whose elements may also be integers or other lists. Implement an iterator to flatten it.Implement the
NestedIteratorclass:
NestedIterator(List<NestedInteger> nestedList): Initializes the iterator with the nested listnestedList.int next(): Returns the next integer in the nested list.boolean hasNext(): Returnstrueif there are still some integers in the nested list andfalseotherwise.Your code will be tested with the following pseudocode:
initialize iterator with nestedList res = [] while iterator.hasNext() append iterator.next() to the end of res return resIf
resmatches the expected flattened list, then your code will be judged as correct.Example 1:
Input: nestedList = [[1,1],2,[1,1]] Output: [1,1,2,1,1] Explanation: By calling next repeatedly until hasNext returns false, the order of elements returned by next should be: [1,1,2,1,1].Example 2:
Input: nestedList = [1,[4,[6]]] Output: [1,4,6] Explanation: By calling next repeatedly until hasNext returns false, the order of elements returned by next should be: [1,4,6].
🧩 Approach
To implement the NestedIterator, we can use a depth-first search (DFS) approach to flatten the nested list of integers. We can maintain a stack to store the integers in the order they should be returned. During the initialization, we can perform a DFS on the input nested list and push all the integers onto the stack. After the DFS is complete, we can reverse the stack to ensure that the integers are in the correct order for iteration. The next() method will simply pop an integer from the stack, and the hasNext() method will check if there are any integers left in the stack.
💡 Solution
from typing import List
# """
# This is the interface that allows for creating nested lists.
# You should not implement it, or speculate about its implementation
# """
#class NestedInteger:
# def isInteger(self) -> bool:
# """
# @return True if this NestedInteger holds a single integer, rather than a nested list.
# """
#
# def getInteger(self) -> int:
# """
# @return the single integer that this NestedInteger holds, if it holds a single integer
# Return None if this NestedInteger holds a nested list
# """
#
# def getList(self) -> [NestedInteger]:
# """
# @return the nested list that this NestedInteger holds, if it holds a nested list
# Return None if this NestedInteger holds a single integer
# """
class NestedIterator:
def __init__(self, nestedList: [NestedInteger]):
"""Initializes the NestedIterator with the given nested list.
Args:
nestedList (List[NestedInteger]): The input nested list of integers.
Returns:
None
"""
self.stack: List[int] = []
self.dfs(nestedList)
self.stack.reverse()
def next(self) -> int:
"""Returns the next integer in the nested list.
Args:
None
Returns:
int: The next integer in the nested list.
"""
return self.stack.pop()
def hasNext(self) -> bool:
"""Returns true if there are still some integers in the nested list and false otherwise.
Args:
None
Returns:
bool: True if there are still some integers in the nested list, False otherwise.
"""
return len(self.stack) > 0
def dfs(self, nested: NestedInteger):
"""Performs a depth-first search on the nested list to flatten it and store the integers in the stack.
Args:
nested (NestedInteger): The current nested list or integer to be processed.
Returns:
None
"""
for n in nested:
if n.isInteger():
self.stack.append(n.getInteger())
else:
self.dfs(n.getList())
🧮 Complexity Analysis
- Time Complexity:
__init__:O(n)for flattening the nested list, wherenis the total number of integers in the nested list.next:O(1)for returning the next integer.hasNext:O(1)for checking if there are more integers to return.
- Space Complexity:
O(n)for storing the flattened integers in the stack.
355. Design Twitter
- LeetCode Link: Design Twitter
- Difficulty: Medium
- Topic(s): Design, Hash Table, Heap, Priority Queue
🧠 Problem Statement
Design a simplified version of
10most recent tweets in the user’s news feed.Implement the
Twitter()Initializes your twitter object.void postTweet(int userId, int tweetId)Composes a new tweet with IDtweetIdby the user with IDuserId. Each call to this function will be made with a uniquetweetId.List<Integer> getNewsFeed(int userId)Retrieves the10most recent tweet IDs in the user’s news feed. Each item in the news feed must be posted by users who the user followed or by the user themself. Tweets must be ordered from most recent to least recent.void follow(int followerId, int followeeId)The user with IDfollowerIdstarted following the user with IDfolloweeId.void unfollow(int followerId, int followeeId)The user with IDfollowerIdstarted unfollowing the user with IDfolloweeId.Example 1:
Input ["Twitter", "postTweet", "getNewsFeed", "follow", "postTweet", "getNewsFeed", "unfollow", "getNewsFeed"] [[], [1, 5], [1], [1, 2], [2, 6], [1], [1, 2], [1]] Output [null, null, [5], null, null, [6, 5], null, [5]] Explanation Twitter twitter = new Twitter(); twitter.postTweet(1, 5); // User 1 posts a new tweet (id = 5). twitter.getNewsFeed(1); // User 1's news feed should return a list with 1 tweet id -> [5]. return [5] twitter.follow(1, 2); // User 1 follows user 2. twitter.postTweet(2, 6); // User 2 posts a new tweet (id = 6). twitter.getNewsFeed(1); // User 1's news feed should return a list with 2 tweet ids -> [6, 5]. Tweet id 6 should precede tweet id 5 because it is posted after tweet id 5. twitter.unfollow(1, 2); // User 1 unfollows user 2. twitter.getNewsFeed(1); // User 1's news feed should return a list with 1 tweet id -> [5], since user 1 is no longer following user 2.
🧩 Approach
To design the Twitter class, we can use a combination of hash maps and a min-heap (priority queue) to efficiently manage tweets and follow relationships. We will maintain a mapping of user IDs to their tweets, as well as a mapping of user IDs to the set of users they follow. When retrieving the news feed for a user, we can use a min-heap to merge the most recent tweets from the user and their followees, ensuring that we return the 10 most recent tweets in the correct order.
💡 Solution
import heapq
from collections import defaultdict
from typing import Dict, List, Set
class Twitter:
"""A simplified Twitter-like social media system.
Supports posting tweets, following/unfollowing users,
and retrieving a user's news feed of the 10 most recent tweets
from themselves and the users they follow.
Attributes:
count (int): A counter used to order tweets by recency (decrements on each post).
tweetMap (Dict[int, List[List[int]]]): Maps each userId to a list of [count, tweetId] pairs.
followMap (Dict[int, Set[int]]): Maps each userId to the set of followeeIds they follow.
"""
def __init__(self) -> None:
"""Initializes the Twitter system with empty tweet and follow maps."""
self.count: int = 0
self.tweetMap: Dict[int, List[List[int]]] = defaultdict(list)
self.followMap: Dict[int, Set[int]] = defaultdict(set)
def postTweet(self, userId: int, tweetId: int) -> None:
"""Posts a new tweet for the given user.
Args:
userId (int): The ID of the user posting the tweet.
tweetId (int): The ID of the tweet being posted.
"""
self.tweetMap[userId].append([self.count, tweetId])
self.count -= 1
def getNewsFeed(self, userId: int) -> List[int]:
"""Retrieves the 10 most recent tweet IDs from the user's news feed.
The feed includes tweets from the user themselves and all users they follow,
sorted in descending order of recency (most recent first).
Args:
userId (int): The ID of the user requesting the news feed.
Returns:
List[int]: A list of up to 10 tweet IDs, ordered from most recent to least recent.
"""
res: List[int] = []
# Min-heap entries are: [count, tweetId, followeeId, index]
# 'count' is negative so lower values = more recent tweets (min-heap acts as max-heap)
minHeap: List[List[int]] = []
# Ensure the user sees their own tweets by adding themselves to their follow set
self.followMap[userId].add(userId)
# Seed the heap with the most recent tweet from each followee
for followeeId in self.followMap[userId]:
if followeeId in self.tweetMap:
# Start from the last (most recent) tweet in the followee's list
index: int = len(self.tweetMap[followeeId]) - 1
count, tweetId = self.tweetMap[followeeId][index]
# Push [count, tweetId, followeeId, next_index] so we can walk backwards later
minHeap.append([count, tweetId, followeeId, index - 1])
# Transform the list into a valid heap in O(n)
heapq.heapify(minHeap)
# Pop the most recent tweet globally, then push the previous tweet from the same user
while minHeap and len(res) < 10:
count, tweetId, followeeId, index = heapq.heappop(minHeap)
# Add the popped tweet to results
res.append(tweetId)
# If this followee has older tweets remaining, push the next one onto the heap
if index >= 0:
count, tweetId = self.tweetMap[followeeId][index]
heapq.heappush(minHeap, [count, tweetId, followeeId, index - 1])
return res
def follow(self, followerId: int, followeeId: int) -> None:
"""Makes a user follow another user.
Args:
followerId (int): The ID of the user who wants to follow.
followeeId (int): The ID of the user to be followed.
"""
self.followMap[followerId].add(followeeId)
def unfollow(self, followerId: int, followeeId: int) -> None:
"""Makes a user unfollow another user.
Args:
followerId (int): The ID of the user who wants to unfollow.
followeeId (int): The ID of the user to be unfollowed.
"""
if followeeId in self.followMap[followerId]:
self.followMap[followerId].remove(followeeId)
🧮 Complexity Analysis
- Time Complexity:
postTweet:O(1)for appending a new tweet.getNewsFeed:O(k log n)where k is the number of followees (including self) and n is the average number of tweets per followee, due to heap operations.follow:O(1)for adding a followee.unfollow:O(1)for removing a followee.
- Space Complexity:
O(u + t)where u is the number of users and t is the total number of tweets, due to storing follow relationships and tweets.
703. Kth Largest Element in a Stream
- LeetCode Link: Kth Largest Element in a Stream
- Difficulty: Easy
- Topic(s): Design, Heap, Priority Queue
- Company: Amazon
🧠 Problem Statement
You are part of a university admissions office and need to keep track of the
kthhighest test score from applicants in real-time. This helps to determine cut-off marks for interviews and admissions dynamically as new applicants submit their scores.You are tasked to implement a class which, for a given integer
k, maintains a stream of test scores and continuously returns thekth highest test score after a new score has been submitted. More specifically, we are looking for thekth highest score in the sorted list of all scores.Implement the
KthLargestclass:
KthLargest(int k, int[] nums)Initializes the object with the integerkand the stream of test scoresnums.int add(int val)Adds a new test scorevalto the stream and returns the element representing thekthlargest element in the pool of test scores so far.Example 1:
Input: ["KthLargest", "add", "add", "add", "add", "add"] [[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]] Output: [null, 4, 5, 5, 8, 8] Explanation: KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]); kthLargest.add(3); // return 4 kthLargest.add(5); // return 5 kthLargest.add(10); // return 5 kthLargest.add(9); // return 8 kthLargest.add(4); // return 8Example 2:
Input: ["KthLargest", "add", "add", "add", "add"] [[4, [7, 7, 7, 7, 8, 3]], [2], [10], [9], [9]] Output: [null, 7, 7, 7, 8] Explanation: KthLargest kthLargest = new KthLargest(4, [7, 7, 7, 7, 8, 3]); kthLargest.add(2); // return 7 kthLargest.add(10); // return 7 kthLargest.add(9); // return 7 kthLargest.add(9); // return 8
🧩 Approach
To maintain the kth largest element in a stream of test scores, we can use a min-heap (priority queue) to store the top k largest elements. The min-heap allows us to efficiently keep track of the smallest element among the top k elements, which will be the kth largest element in the stream. When a new score is added, we can compare it with the smallest element in the heap. If the new score is larger than the smallest element, we can remove the smallest element and add the new score to the heap. This way, we ensure that the heap always contains the k largest elements from the stream.
💡 Solution
from typing import List
import heapq
class KthLargest:
def __init__(self, k: int, nums: List[int]):
"""Initializes the KthLargest object with the given integer k and the stream of test scores nums.
Args:
k (int): The integer k representing the rank of the largest element to maintain.
nums (List[int]): The initial stream of test scores.
Returns:
None
"""
self.__minHeap: List[int] = nums
self.__k: int = k
heapq.heapify(self.__minHeap)
while len(self.__minHeap) > k:
heapq.heappop(self.__minHeap)
def add(self, val: int) -> int:
"""Adds a new test score val to the stream and returns the element representing the kth largest element in the pool of test scores so far.
Args:
val (int): The new test score to be added to the stream.
Returns:
int: The kth largest element in the stream after adding the new score.
"""
heapq.heappush(self.__minHeap, val)
if len(self.__minHeap) > self.__k:
heapq.heappop(self.__minHeap)
return self.__minHeap[0]
🧮 Complexity Analysis
- Time Complexity:
__init__:O(n log k)for building the heap and maintaining the topkelements.add:O(log k)for adding a new score and maintaining the heap.
- Space Complexity:
O(k)for storing the topkelements in the heap.
705. Design HashSet
- LeetCode Link: Design HashSet
- Difficulty: Easy
- Topic(s): Design, Hash Table
- Company: Meta
🧠 Problem Statement
Design a HashSet without using any built-in hash table libraries.
Implement
MyHashSetclass:
void add(key)Inserts the valuekeyinto the HashSet.bool contains(key)Returns whether the valuekeyexists in the HashSet or not.void remove(key)Removes the valuekeyin the HashSet. If key does not exist in the HashSet, do nothing.Example 1:
Input ["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"] [[], [1], [2], [1], [3], [2], [2], [2], [2]] Output [null, null, null, true, false, null, true, null, false] Explanation MyHashSet myHashSet = new MyHashSet(); myHashSet.add(1); // set = [1] myHashSet.add(2); // set = [1, 2] myHashSet.contains(1); // return True myHashSet.contains(3); // return False, (not found) myHashSet.add(2); // set = [1, 2] myHashSet.contains(2); // return True myHashSet.remove(2); // set = [1] myHashSet.contains(2); // return False, (already removed)
🧩 Approach
To design a HashSet, we can use an array of linked lists (chaining) to handle collisions. We can define a ListNode class to represent each node in the linked list, which will store the key and a reference to the next node. The MyHashSet class will contain an array of ListNode objects, where each index corresponds to a hash value derived from the key. When adding a key, we will compute its hash value and insert it into the corresponding linked list. For checking if a key exists or for removing a key, we will traverse the linked list at the computed hash index to find the key.
💡 Solution
from typing import Optional, List
class ListNode:
def __init__(self, key: int):
"""Initializes a ListNode with the given key.
Args:
key (int): The value to be stored in the ListNode.
Returns:
None
"""
self.key: int = key
self.next: Optional[ListNode] = None
class MyHashSet:
def __init__(self):
"""Initializes an empty HashSet."""
self.__set: List[ListNode] = [ListNode(0) for _ in range(10**4)]
def add(self, key: int) -> None:
"""Inserts the value key into the HashSet.
Args:
key (int): The value to be added to the HashSet.
Returns:
None
"""
cur: ListNode = self.__set[key % len(self.__set)]
while cur.next:
if cur.next.key == key:
return None
cur = cur.next
cur.next = ListNode(key)
def remove(self, key: int) -> None:
"""Removes the value key in the HashSet. If key does not exist in the HashSet, do nothing.
Args:
key (int): The value to be removed from the HashSet.
Returns:
None
"""
cur: ListNode = self.__set[key % len(self.__set)]
while cur.next:
if cur.next.key == key:
cur.next = cur.next.next
return None
cur = cur.next
def contains(self, key: int) -> bool:
"""Returns whether the value key exists in the HashSet or not.
Args:
key (int): The value to check for existence in the HashSet.
Returns:
bool: True if the value exists in the HashSet, False otherwise.
"""
cur: ListNode = self.__set[key % len(self.__set)]
while cur.next:
if cur.next.key == key:
return True
cur = cur.next
return False
🧮 Complexity Analysis
- Time Complexity:
add:O(1)on average, butO(n)in the worst case due to collision handling with chaining.remove:O(1)on average, butO(n)in the worst case due to collision handling with chaining.contains:O(1)on average, butO(n)in the worst case due to collision handling with chaining.
- Space Complexity:
O(n)
706. Design HashMap
- LeetCode Link: Design HashMap
- Difficulty: Easy
- Topic(s): Design, Hash Table
- Company: Google
🧠 Problem Statement
Design a HashMap without using any built-in hash table libraries.
Implement the
MyHashMapclass:
MyHashMap()initializes the object with an empty map.void put(int key, int value)inserts a(key, value)pair into the HashMap. If thekeyalready exists in the map, update the correspondingvalue.int get(int key)returns thevalueto which the specifiedkeyis mapped, or-1if this map contains no mapping for thekey.void remove(key)removes thekeyand its correspondingvalueif the map contains the mapping for thekey.Example 1:
Input ["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"] [[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]] Output [null, null, null, 1, -1, null, 1, null, -1] Explanation MyHashMap myHashMap = new MyHashMap(); myHashMap.put(1, 1); // The map is now [[1,1]] myHashMap.put(2, 2); // The map is now [[1,1], [2,2]] myHashMap.get(1); // return 1, The map is now [[1,1], [2,2]] myHashMap.get(3); // return -1 (i.e., not found), The map is now [[1,1], [2,2]] myHashMap.put(2, 1); // The map is now [[1,1], [2,1]] (i.e., update the existing value) myHashMap.get(2); // return 1, The map is now [[1,1], [2,1]] myHashMap.remove(2); // remove the mapping for 2, The map is now [[1,1]] myHashMap.get(2); // return -1 (i.e., not found), The map is now [[1,1]]
🧩 Approach
To design a HashMap, we can use an array of linked lists (chaining) to handle collisions, similar to the design of a HashSet. We can define a ListNode class to represent each node in the linked list, which will store the key, value, and a reference to the next node. The MyHashMap class will contain an array of ListNode objects, where each index corresponds to a hash value derived from the key. When adding a key-value pair, we will compute its hash value and insert it into the corresponding linked list. For checking if a key exists or for removing a key, we will traverse the linked list at the computed hash index to find the key and perform the necessary operations.
💡 Solution
from typing import Optional, List
class ListNode:
def __init__(self, key: int, value: int):
self.key: int = key
self.value: int = value
self.next: Optional[ListNode] = None
class MyHashMap:
def __init__(self):
self.__map: List[ListNode] = [ListNode(0, 0) for _ in range(10**4)]
def put(self, key: int, value: int) -> None:
cur: ListNode = self.__map[key % len(self.__map)]
while cur.next:
if cur.next.key == key:
cur.next.value = value
return None
cur = cur.next
cur.next = ListNode(key, value)
def get(self, key: int) -> int:
cur: ListNode = self.__map[key % len(self.__map)]
while cur.next:
if cur.next.key == key:
return cur.next.value
cur = cur.next
return -1
def remove(self, key: int) -> None:
cur: ListNode = self.__map[key % len(self.__map)]
while cur.next:
if cur.next.key == key:
cur.next = cur.next.next
return None
cur = cur.next
🧮 Complexity Analysis
- Time Complexity:
put:O(1)on average, butO(n)in the worst case due to collision handling with chaining.get:O(1)on average, butO(n)in the worst case due to collision handling with chaining.remove:O(1)on average, butO(n)in the worst case due to collision handling with chaining.
- Space Complexity:
O(n)for storing the key-value pairs in the hash map.
933. Number of Recent Calls
- LeetCode Link: Number of Recent Calls
- Difficulty: Easy
- Topic(s): Design, Queue
- Company: Amazon
🧠 Problem Statement
You have a
RecentCounterclass which counts the number of recent requests within a certain time frame.Implement the
RecentCounterclass:
RecentCounter()Initializes the counter with zero recent requests.int ping(int t)Adds a new request at timet, wheretrepresents some time in milliseconds, and returns the number of requests that has happened in the past3000milliseconds (including the new request). Specifically, return the number of requests that have happened in the inclusive range[t - 3000, t].It is guaranteed that every call to
pinguses a strictly larger value oftthan the previous call.Example 1:
Input ["RecentCounter", "ping", "ping", "ping", "ping"] [[], [1], [100], [3001], [3002]] Output [null, 1, 2, 3, 3] Explanation RecentCounter recentCounter = new RecentCounter(); recentCounter.ping(1); // requests = [1], range is [-2999,1], return 1 recentCounter.ping(100); // requests = [1, 100], range is [-2900,100], return 2 recentCounter.ping(3001); // requests = [1, 100, 3001], range is [1,3001], return 3 recentCounter.ping(3002); // requests = [1, 100, 3001, 3002], range is [2,3002], return 3
🧩 Approach
To count the number of recent requests within a certain time frame, we can use a queue (specifically, a deque) to store the timestamps of the requests. When a new request is added using the ping method, we will add its timestamp to the back of the queue. Then, we will remove any timestamps from the front of the queue that are outside the range of [t - 3000, t]. Finally, we can return the size of the queue, which will represent the number of requests that have happened in the past 3000 milliseconds.
💡 Solution
from collections import deque
class RecentCounter:
def __init__(self):
"""Initializes the RecentCounter object with zero recent requests."""
self.__requests: deque[int] = deque()
def ping(self, t: int) -> int:
"""Adds a new request at time t and returns the number of requests that has happened in the past 3000 milliseconds.
Args:
t (int): The time in milliseconds when the new request is added.
Returns:
int: The number of requests that have happened in the inclusive range [t - 3000, t].
"""
self.__requests.append(t)
while self.__requests and self.__requests[0] < t - 3000:
self.__requests.popleft()
return len(self.__requests)
🧮 Complexity Analysis
- Time Complexity:
ping:O(1)on average, butO(n)in the worst case when all requests are outside the 3000 milliseconds range and need to be removed.
- Space Complexity:
O(n)for storing the requests in the deque.
1603. Design Parking System
- LeetCode Link: Design Parking System
- Difficulty: Easy
- Topic(s): Design
- Company: Amazon
🧠 Problem Statement
Design a parking system for a parking lot. The parking lot has three kinds of parking spaces: big, medium, and small, with a fixed number of slots for each size.
Implement the
ParkingSystemclass:
ParkingSystem(int big, int medium, int small)Initializes object of theParkingSystemclass. The number of slots for each parking space are given as part of the constructor.bool addCar(int carType)Checks whether there is a parking space ofcarTypefor the car that wants to get into the parking lot.carTypecan be of three kinds: big, medium, or small, which are represented by1,2, and3respectively. A car can only park in a parking space of itscarType. If there is no space available, returnfalse, else park the car in that size space and returntrue.Example 1:
Input ["ParkingSystem", "addCar", "addCar", "addCar", "addCar"] [[1, 1, 0], [1], [2], [3], [1]] Output [null, true, true, false, false] Explanation ParkingSystem parkingSystem = new ParkingSystem(1, 1, 0); parkingSystem.addCar(1); // return true because there is 1 available slot for a big car parkingSystem.addCar(2); // return true because there is 1 available slot for a medium car parkingSystem.addCar(3); // return false because there is no available slot for a small car parkingSystem.addCar(1); // return false because there is no available slot for a big car. It is already occupied.
🧩 Approach
To design the parking system, we can use a simple list to keep track of the available parking spaces for each car type. The list will have three elements corresponding to the number of available slots for big, medium, and small cars. When a car tries to park, we can check if there is an available slot for that car type by checking the corresponding element in the list. If there is an available slot, we can decrement the count for that car type and return true. If there are no available slots, we return false.
💡 Solution
from typing import List
class ParkingSystem:
def __init__(self, big: int, medium: int, small: int):
self.__spaces: List[int] = [big, medium, small]
def addCar(self, carType: int) -> bool:
if self.__spaces[carType - 1] > 0:
self.__spaces[carType - 1] -= 1
return True
return False
🧮 Complexity Analysis
- Time Complexity:
addCar:O(1)for checking and updating the available slots.
- Space Complexity:
O(1)for storing the available slots for each car type.
1656. Design an Ordered Stream
- LeetCode Link: Design an Ordered Stream
- Difficulty: Easy
- Topic(s): Design
- Company: Google
🧠 Problem Statement
There is a stream of
n(idKey, value)pairs arriving in an arbitrary order, whereidKeyis an integer between1andnandvalueis a string. No two pairs have the sameid.Design a stream that returns the values in increasing order of their IDs by returning a chunk (list) of values after each insertion. The concatenation of all the chunks should result in a list of the sorted values.
Implement the
OrderedStreamclass:
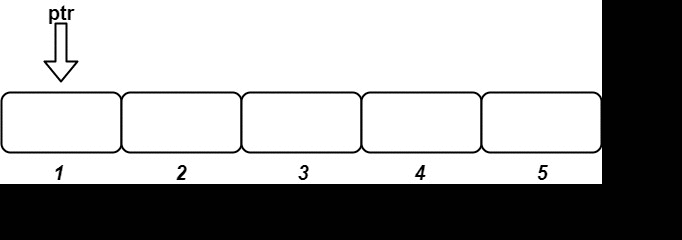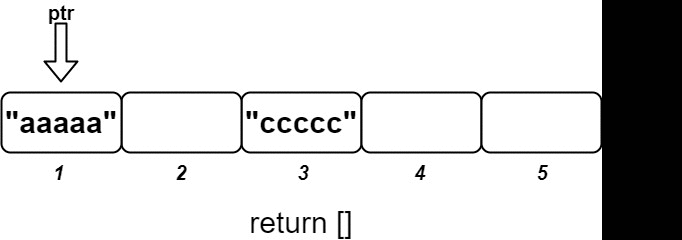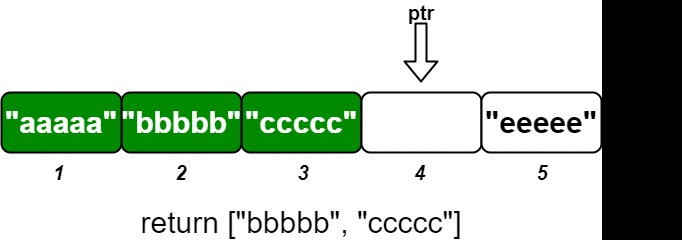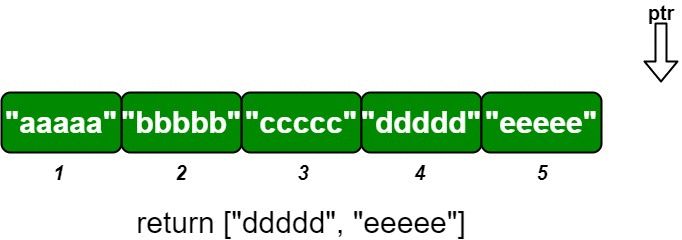
OrderedStream(int n)Constructs the stream to takenvalues.String[] insert(int idKey, String value)Inserts the pair(idKey, value)into the stream, then returns the largest possible chunk of currently inserted values that appear next in the order.Example:
Input ["OrderedStream", "insert", "insert", "insert", "insert", "insert"] [[5], [3, "ccccc"], [1, "aaaaa"], [2, "bbbbb"], [5, "eeeee"], [4, "ddddd"]] Output [null, [], ["aaaaa"], ["bbbbb", "ccccc"], [], ["ddddd", "eeeee"]] Explanation // Note that the values ordered by ID is ["aaaaa", "bbbbb", "ccccc", "ddddd", "eeeee"]. OrderedStream os = new OrderedStream(5); os.insert(3, "ccccc"); // Inserts (3, "ccccc"), returns []. os.insert(1, "aaaaa"); // Inserts (1, "aaaaa"), returns ["aaaaa"]. os.insert(2, "bbbbb"); // Inserts (2, "bbbbb"), returns ["bbbbb", "ccccc"]. os.insert(5, "eeeee"); // Inserts (5, "eeeee"), returns []. os.insert(4, "ddddd"); // Inserts (4, "ddddd"), returns ["ddddd", "eeeee"]. // Concatenating all the chunks returned: // [] + ["aaaaa"] + ["bbbbb", "ccccc"] + [] + ["ddddd", "eeeee"] = ["aaaaa", "bbbbb", "ccccc", "ddddd", "eeeee"] // The resulting order is the same as the order above.
🧩 Approach
To design the ordered stream, we can use a list to store the values corresponding to their IDs. We will maintain a pointer that keeps track of the next ID that we need to return in order. When a new (idKey, value) pair is inserted, we will store the value at the index corresponding to idKey - 1 in the list. After inserting the new value, we will check if the value at the current pointer index is available (not None). If it is available, we will keep moving the pointer forward until we find a None value or reach the end of the list. We will then return the chunk of values from the original pointer position to the new pointer position.
💡 Solution
from typing import Optional, List
class OrderedStream:
def __init__(self, n: int):
"""Constructs the stream to take n values.
Args:
n (int): The number of values the stream can take.
Returns:
None
"""
self.__ptr: int = 0
self.__data: List[Optional[str]] = [None] * n
def insert(self, idKey: int, value: str) -> List[str]:
"""Inserts the pair (idKey, value) into the stream, then returns the largest possible chunk of currently inserted values that appear next in the order.
Args:
idKey (int): The ID key of the value to be inserted.
value (str): The value to be inserted.
Returns:
List[str]: The largest possible chunk of currently inserted values that appear next in the order.
"""
idx: int = idKey - 1
self.__data[idx] = value
if idx != self.__ptr:
return []
n = len(self.__data)
while self.__ptr < n and self.__data[self.__ptr] is not None:
self.__ptr += 1
return self.__data[idx:self.__ptr]
🧮 Complexity Analysis
- Time Complexity:
insert:O(1)for inserting a value, butO(n)in the worst case when all values are inserted in order and we need to return a chunk of sizen.
- Space Complexity:
O(n)for storing the values in the stream.
3242. Design Neighbor Sum Service
- LeetCode Link: Design Neighbor Sum Service
- Difficulty: Easy
- Topic(s): Design
- Company: Google
🧠 Problem Statement
You are given a
n x n2D arraygridcontaining distinct elements in the range[0, n^2 - 1].Implement the
NeighborSumclass:
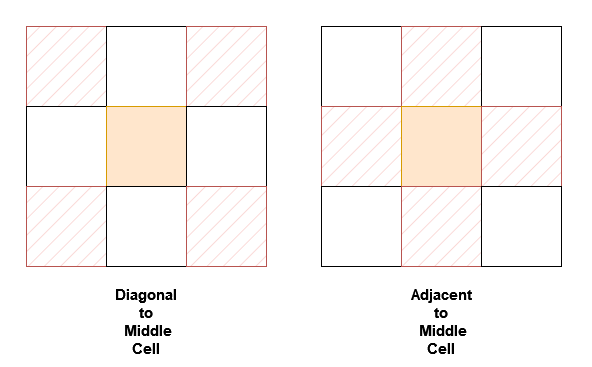
NeighborSum(int [][]grid)initializes the object.int adjacentSum(int value)returns the sum of elements which are adjacent neighbors ofvalue, that is either to the top, left, right, or bottom ofvalueingrid.int diagonalSum(int value)returns the sum of elements which are diagonal neighbors ofvalue, that is either to the top-left, top-right, bottom-left, or bottom-right ofvalueingrid.
Example 1:
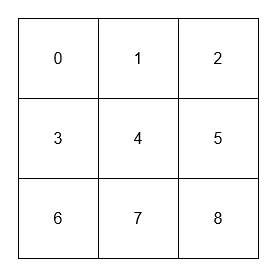
Input: ["NeighborSum", "adjacentSum", "adjacentSum", "diagonalSum", "diagonalSum"] [[[[0, 1, 2], [3, 4, 5], [6, 7, 8]]], [1], [4], [4], [8]] Output: [null, 6, 16, 16, 4] Explanation: - The adjacent neighbors of 1 are 0, 2, and 4. - The adjacent neighbors of 4 are 1, 3, 5, and 7. - The diagonal neighbors of 4 are 0, 2, 6, and 8. - The diagonal neighbor of 8 is 4.Example 2:
Input: ["NeighborSum", "adjacentSum", "diagonalSum"] [[[[1, 2, 0, 3], [4, 7, 15, 6], [8, 9, 10, 11], [12, 13, 14, 5]]], [15], [9]] Output: [null, 23, 45] Explanation: - The adjacent neighbors of 15 are 0, 10, 7, and 6. - The diagonal neighbors of 9 are 4, 12, 14, and 15.
🧩 Approach
Use a lookup table (hash map) to store the coordinates of each value in the grid for O(1) access. For both adjacentSum and diagonalSum, we can define the relative positions of the neighbors and iterate through them to calculate the sum, while ensuring that we stay within the bounds of the grid.
💡 Solution
from typing import List, Tuple
class NeighborSum:
def __init__(self, grid: List[List[int]]):
"""Initializes the NeighborSum object with the given 2D array grid.
Args:
grid (List[List[int]]): The 2D array containing distinct elements.
Returns:
None
"""
self.__grid: List[List[int]] = grid
self.__R: int = len(grid)
self.__C: int = len(grid[0])
self.__lookup: dict[int, Tuple[int, int]] = {}
for x in range(self.__R):
for y in range(self.__C):
self.__lookup[grid[x][y]] = (x, y)
def adjacentSum(self, value: int) -> int:
"""Returns the sum of elements which are adjacent neighbors of value, that is either to the top, left, right, or bottom of value in grid.
Args:
value (int): The value for which to calculate the adjacent sum.
Returns:
int: The sum of adjacent neighbors of the given value.
"""
x, y = self.__lookup[value]
total: int = 0
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
nx: int = x + dx
ny: int = y + dy
if 0 <= nx < self.__R and 0 <= ny < self.__C:
total += self.__grid[nx][ny]
return total
def diagonalSum(self, value: int) -> int:
"""Returns the sum of elements which are diagonal neighbors of value, that is either to the top-left, top-right, bottom-left, or bottom-right of value in grid.
Args:
value (int): The value for which to calculate the diagonal sum.
Returns:
int: The sum of diagonal neighbors of the given value.
"""
x, y = self.__lookup[value]
total: int = 0
for dx, dy in [(-1, -1), (1, 1), (1, -1), (-1, 1)]:
nx: int = x + dx
ny: int = y + dy
if 0 <= nx < self.__R and 0 <= ny < self.__C:
total += self.__grid[nx][ny]
return total
🧮 Complexity Analysis
- Time Complexity:
adjacentSum:O(1)since we only check 4 adjacent neighbors.diagonalSum:O(1)since we only check 4 diagonal neighbors.
- Space Complexity:
O(n^2)for storing the grid and lookup table.